最简单的 awk 程序是一个由多个 模式–动作 语句构成的序列:
pattern { action }
pattern { action }
…
在某些语句中, 模式可以不存在; 还有些语句, 动作及其包围它的花括号也可以不存在. 如果程序经过
awk 检查后没有发现语法错误, 它就会每次读取一个输入行, 对读取到的每一行, 按顺序检查每一个模
式. 对每一个与当前行匹配的模式, 对应的动作就会执行. 一个缺失的模式匹配每一个输入行, 因此每一
个不带有模式的动作对每一个输入行都会执行. 只含有模式而没有动作的语句, 会打印每一个匹配模式
的输入行. 大部分情况下, 在这一章出现的术语 “输入行” 与 “记录” 被当作一对同义词.
输入文件 countries
作为本章许多 awk 程序的输入数据, 我们将使用文件 countries. 每一行都包括一
个国家的名字, 面积 (以千平方英里为单位), 人口 (以百万为单位), 以及这个国家所在的大
陆. 数据来源于 1984 年, 苏联被归到了亚洲. 在文件里, 四列数据用制表符分隔, 用一个空
格分隔 North (South) 与 America.
文件 countries 包含下面几行: 22
USSR 8649 275 Asia
Canada 3852 25 North America
China 3705 1032 Asia
USA 3615 237 North America
Brazil 3286 134 South America
India 1267 746 Asia
Mexico 762 78 North America
France 211 55 Europe
Japan 144 120 Asia
Germany 96 61 Europe
England 94 56 Europe
在这一章的剩下部分里, 如果没有显式给出输入数据, 默认将 countries 作为输入.
程序格式
模式–动作 语句, 以及动作内的语句通常用换行符分隔, 但是若干条语句也可以出现在同一行, 只要它们之间用分号分开即可. 一个分号可以放在任何语句的末尾.
动作的左花括号必须与它的模式在同一行; 而剩下的部分, 包括右花括号, 则可以出现
在下面几行.
空行会被忽略; 它们可以插入在语句之前或之后, 用于提高程序的可读性. 空格与制表
符可以出现在运算符与操作数的周围, 同样也是为了提高可读性.
注释可以出现在任意一行的末尾. 一个注释以井号 (#) 开始, 以换行符结束, 正如
{ print $1, $3 } # print country name and population
一条长语句可以分散成多行, 只要在断行处插入一个反斜杠即可:
{ print \
$1, # country name
$2, # area in thousands of square miles
$3 } # population in millions
正如这个例子所呈现的那样, 语句可以在逗号之后断行, 并且注释可以出现在断行的末尾.在这本书里我们用到了若干种编程风格, 之所以这样做, 一方面是为了比较不同风格之间的差异, 另一方面是为了避免程序占用过多的行. 对于比较短小的程序 — 就像本章中出现过的那些例子 — 格式并不是非常重要, 但是一致性与可读性对于大程序的管理非常有帮助.
模式
模式控制着动作的执行: 当模式匹配时, 相应的动作便会执行. 这一小节描述模式的 6
种类型, 以及匹配它们的条件.
模式汇总
BEGIN{ statements}
在输入被读取之前, statements 执行一次.END{ statements}
当所有输入被读取完毕之后, statements 执行一次.expression{ statements}
每碰到一个使 expression 为真的输入行, statements 就执行. expression 为真指的是其值非零或非空./regular expression/ { statements}
当碰到这样一个输入行时, statements 就执行: 输入行含有一段字符串, 而该字符串可以被 regular expression 匹配.compound pattern { statements}
一个复合模式将表达式用&&(AND),||(OR),!(NOT),以及括号组合起来; 当com-pound pattern 为真时, statements 执行.pattern 1 , pattern 2 { statements}
一个范围模式匹配多个输入行, 这些输入行从匹配 pattern 1 的行开始, 到匹配 pat-tern 2 的行结束 (包括这两行), 对这其中的每一行执行 statements. BEGIN 与 END 不与其他模式组合. 一个范围模式不能是其他模式的一部分. BEGIN 与END 是唯一两个不能省略动作的模式.符. 将 FS 设置成一个非空格字符, 就会使该字符成为字段分割符.下面这个程序在 BEGIN 的动作里将字段字割符设置为制表符 (\t), 并在输出之前打印标题. 第二个 printf 语句 (对每一个输入行它都会执行) 将输出格式化成一张表格, 使得每一列都刚好与标题的列表头对齐. END 打印总和.
BEGIN 与 与 END
BEGIN 与 END 这两个模式不匹配任何输入行. 实际情况是, 当 awk 从输入读取数据之前, BEGIN 的语句开始执行; 当所有输入数据被读取完毕, END 的语句开始执行. 于是,BEGIN 与 END 分别提供了一种控制初始化与扫尾的方式. BEGIN 与 END 不能与其他模式作组合. 如果有多个 BEGIN, 与其关联的动作会按照它们在程序中出现的顺序执行, 这种行为对多个 END 同样适用. 我们通常将 BEGIN 放在程序开头, 将 END 放在程序末尾, 虽然这并不是强制的.
BEGIN 的一个常见用途是更改输入行被分割为字段的默认方式. 分割字符由一个内建变量 FS 控制. 默认情况下字段由空格或 (和) 制表符分割, 此时 FS 的值被设置为一个空格符. 将 FS 设置成一个非空格字符, 就会使该字符成为字段分割符.
下面这个程序在 BEGIN 的动作里将字段字割符设置为制表符 (\t), 并在输出之前打印标题. 第二个 printf 语句 (对每一个输入行它都会执行) 将输出格式化成一张表格, 使得每一列都刚好与标题的列表头对齐. END 打印总和.
print countries with column headers and totals
BEGIN { FS = “\t” # make tab the field separator
printf(“%10s %6s %5s %s\n\n”,
“COUNTRY”, “AREA”, “POP”, “CONTINENT”)
}
{ printf(“%10s %6d %5d %s\n”, $1, $2, $3, $4)
area = area + $2
pop = pop + $3
}
END { printf(“\n%10s %6d %5d\n”, “TOTAL”, area, pop) }
如果将 countries 作为输入, 将出将是
COUNTRY AREA POP CONTINENT
USSR 8649 275 Asia
Canada 3852 25 North America
China 3705 1032 Asia
USA 3615 237 North America
Brazil 3286 134 South America
India 1267 746 Asia
Mexico 762 78 North America
France 211 55 Europe
Japan 144 120 Asia
Germany 96 61 Europe
England 94 56 Europe
TOTAL 25681 2819
将表达式用作模式
就像大多数程序设计语言一样,awk拥有非常丰富的用来描述数值计算的表达式,但是与许多语言不同的是,awk还有用于描述字符串操作的表达式.贯穿全书, string 都表示一个由 0 个或多个字符组成的序列. 这些字符串可以存储在变量中, 也可以以字符串常量的形式出现, 就像 “” 或 “Asia”. 字符串 “” 不包括任何字符, 叫做 空字符串 (null string). 术语 串 子字符串 (substring) 表示一个字符串内部的, 由 0 个或多个字符组成的连续序列. 对任意一个字符串, 空字符串都可以看作是该字符串第一个字符之前的, 长度为 0 的子字符串,或者是一对相邻字符之间的子字符串, 又或者是最后一个字符之后的子字符串.任意一个表达式都可以用作任意一个运算符的操作数. 如果一个表达式拥有一个数值形式的值, 而运算符要求一个字符串值, 那么该数值会自动转换成字符串, 类似地, 当运算符 25要求一个数值时, 字符串被自动转换成数值.任意一个表达式都可以当作模式来使用. 如果一个作为模式使用的表达式, 对当前输入行的求值结果不空或非零, 那么该模式就匹配该行. 典型的表达式模式是那些涉及到数值或
字符串比较的表达式. 一个比较表达式包含 6 种关系运算符中的一种, 或者包含两种字符串
匹配运算符中的一种: ~ 与 !~ 在下一小节讨论. 关系运算符如下图:
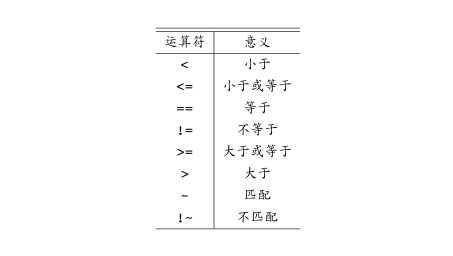
如果模式是一个比较表达式, 就像 NF > 10, 当当前行使该条件满足时, 这个模式就算是匹配该输入行, 在这里条件满足指的是当前输入行的字段数大于 10. 如果模式是一个算术表达式, 就像 NF, 如果该表达式的值非零, 那么当前输入行被匹配. 如果模式是一个字符串表达式, 当表达式的字符串值非空时, 当前输入行被匹配.
在一个关系比较中, 如果两个操作数都是数值, 关系比较将会按照数值比较进行; 否则的话, 数值操作数会被转换成字符串, 再将操作数按字符串的形式进行比较. 两个字符串间的比较以字符为单位逐个相比, 字符间的先后顺序依赖于机器的字符集 (大多数情况下是 ASCII 字符集). 一个字符串 “小于” 另一个, 指的是它比另一个字符串更早出现, 例如:
“Canada” < “China”, “Asia” < “Asian”.
模式
\$3/$2 >= 0.5
选择的行, 其第 3 个字段除以第 2 个字段所得的商大于 0.5, 而
$0 >= “M”
26
选择那些以字母 M, N, O 等开头的输入行:
USSR 8649 275 Asia
USA 3615 237 North America
Mexico 762 78 North America
有时候一个比较运算符的类型不能单单靠表达式表现出来的语法形式来判断. 程序
\$1 < $4
可以以数值的形式, 或者字符串的形式比较输入行的第 1 个与第 4 个字段. 在这里, 比较的类型取决于字段的值, 并且有可能每一行都有不同的情况出现. 文件 countries 的第 1 个与第 4 个字段总是字符串, 所以比较总是以字符串的形式进行; 输出是
Canada 3852 25 North America
Brazil 3286 134 South America
Mexico 762 78 North America
England 94 56 Europe
只有当两个字段都是数值时, 比较才会以数值的形式进行; 这种情况可以是
\$2 < $3
字符串匹配模式
Awk 提供了一种称为 正则表达式 (regular expression) 的表示法, 它可以用来指定和匹配一个字符串. 正则表达式在 Unix 环境用得非常普遍, 包括文本编辑器与 shell. 受限形式的正则表达式也出现在其他系统中, 在 MS-DOS 中可以用 “通配符” 指定一个文件名集合.
一个 式 字符串匹配模式 (string-matching pattern) 测试一个字符串是否包含一段可以被正则表达式匹配的子字符串.
最简单的正则表达式是仅由数字与字母组成的字符串, 就像 Asia, 它匹配的就是它本身. 为了将一个正则表达式切换成一个模式, 只需要用一对斜杠包围起来即可:
/Asia/
这个模式匹配那些含有子字符串 Asia 的输入行, 例如 Asia, Asian, 或 Pan-Asiatic.
注意, 正则表达式中空格是有意义的: 字符串匹配模式
字符串匹配模式
- /regexpr/
当当前输入行包含一段能够被 regexpr 匹配的子字符串时, 该模式被匹配. - expression ~ /regexpr/
如果 expression 的字符串值包含一段能够被 regexpr 匹配的子字符时, 该模式被
匹配. - expression !~ /regexpr/
如果 expression 的字符串值不包含能够被 regexpr 匹配的子字符串, 该模式被匹
配.
在 ~ 与 !~ 的语境中, 任意一个表达式都可以用来替换 /regexpr/.
/ Asia /
只有当 Asia 被一对空格包围时才会匹配成功.
上面的模式是三种字符串匹配模式当中的一种. 它的形式是用一对斜杠将正则表达式
包围起来:
/r/
如果某个输入行含有能被 r 匹配的子字符串, 则该行匹配成功.
剩下的两种字符串匹配模式使用到了显式的匹配运算符:
expression ~ /r/
expression !~ /r/
匹配运算符 ~ 的意思是 “被… 匹配”, !~ 的意思是 “不被… 匹配”. 当 expression 的字符串值
包含一段能够被正则表达式 r 匹配的子字串时, 第一个模式被匹配; 当不存在这样的子字符
串时, 第二个模式被匹配.
匹配运算符的左操作数经常是一个字段, 模式
$4 ~ /Asia/
匹配所有第 4 个字段包含 Asia 的输入行, 而
$4 !~ /Asia/
匹配所有第 4 个字段 不包含 Asia 的输入行.
注意到, 字符串匹配模式
/Asia/
是
$0 ~ /Asia/
的简写形式.
正则表达式
正则表达式是一种用于指定和匹配字符串的表示法. 就像算术表达式一样, 一个正则表达式是一个基本表达式, 或者是多个子表达式通过运算符组合而成. 为了理解被一个正则表达式匹配的字符串, 我们需要先了解被子表达式匹配的字符串.
正则表达式
- 正则表达式的元字符包括:
\ ^ $ . [ ] | ( ) * + ? - 一个基本的正则表达式包括下面几种:
一个不是元字符的字符, 例如 A, 这个正则表达式匹配的就是它本身.
一个匹配特殊符号的转义字符: \t 匹配一个制表符 (见表 2.2).
一个被引用的元字符, 例如 *, 按字面意义匹配元字符.
^ 匹配一行的开始.
$ 匹配一行的结束.
. 匹配任意一个字符.
一个字符类: [ABC] 匹配字符 A, B 或 C.
字符类可能包含缩写形式: [A-Za-z] 匹配单个字母.
一个互补的字符类: [^0-9] 匹配任意一个不是数字的字符. - 这些运算符将正则表达式组合起来:
选择: A|B 匹配 A 或 B.
拼接: AB 匹配后面紧跟着 B 的 A.
闭包: A* 匹配 0 个或多个 A.
正闭包: A+ 匹配一个或多个 A.
零或一: A? 匹配空字符串或 A.
括号: 被 (r) 匹配的字符串, 与 r 所匹配的字符串相同.
基本的正则表达式在上面的表格中列出. 字符
\ ^ $ . [ ] | ( ) * + ?
叫作 符 元字符 (metacharacter), 之所以这样称呼是因为它们具有特殊的意义. 一个由单个非
元字符构成的正则表达式匹配它自身. 于是, 一个字母或一个数字都算作是一个基本的正则
表达式, 与自身相匹配. 为了在正则表达式中保留元字符的字面意义, 需要在字符的前面加
上反斜杠. 于是, \$ 匹配普通字符 $. 如果某个字符前面冠有 \, 我们就说该字符是被 引用
(quoted) 的.
在一个正则表达式中, 一个未被引用的脱字符 ^ 表示一行的开始, 一个未被引用的美元
符 $ 匹配一行的结束, 一个未被引用的句点 . 匹配任意一个字符. 于是,
^C 匹配以字符 C 开始的字符串;
C$ 匹配以字符 C 结束的字符串;
^C$ 匹配只含有单个字符 C 的字符串;
^.$ 匹配有且仅有一个字符的字符串;
^…$ 匹配有且仅有 3 个字符的字符串;
… 匹配任意 3 个字符;
.$ 匹配以句点结束的字符串.
由一组被包围在方括号中的字符组成的正则表达式称为 类 字符类 (character class); 这个表达式匹配字符类中的任意一个字符. 例如, [AEIOU] 匹配 A, E, I, O 或 U.使用连字符的字符类可以表示一段字符范围. 紧跟在连字符左边的字符定义了范围的开始, 紧跟在连字符右边的字符定义了范围的结束. 于是, [0-9] 匹配任意一个数字,[a-zA-Z][0-9] 匹配一个后面紧跟着一个数字的字母. 如果左右两边都没有操作数, 那么字符类中的连字符就表示它本身, 所以 [+-] 与 [-+] 匹配一个 + 或 -. [A-Za-z-]+ 匹配一个可能包含连字符的单词.
一个 补 互补 (complemented) 的字符类在 [ 之后以 ^ 开始. 这样一个类匹配任意一个不在类中的字符, “类中的字符” 指的是方括号内排在脱字符之后的那些字符. 于是, [^0-9]匹配任意一个不是数字的字符; [^a-zA-Z] 匹配任意一个不是字母的字符.
^[ABC] 匹配以 A, B, 或 C 开始的字符串;
^[^ABC] 匹配以任意一个字符 (除了 A, B, 或 C) 开始的字符串;
[^ABC] 匹配任意一个字符, 除了 A, B, 或 C;
^[^a-z]$ 匹配任意一个有且仅有一个字符的字符串, 且该字符不能是小写字母.
在一个字符类中, 所有的字符都具有它自身的字面意义, 除了引用字符 \, 互补字符类开头的 ^, 以及两个字符间的 -. 于是, [.] 匹配一个句点, ^[^^] 匹配不以脱字符开始的字符串.
可以使用括号来指定正则表达式中的各个成分如何组合. 有两种二元正则表达式运算符: 选择与拼接. 选择运算符 | 用来指定一个选择: 如果 r 1 与 r 2 是正则表达式, 那么 r 1 |r 2所匹配的字符串, 或者与 r 1 , 或者与 r 2 匹配.
Awk 不存在显式的拼接运算符. 如果 r 1 与 r 2 是正则表达式, 那么 (r 1 )(r 1 ) (在 (r 1 )与 (r 2 ) 之间没有空格) 所匹配的字符串具有形式 xy, 其中 x 被 r 1 匹配, y 被 r 2 匹配. 如果被括号包围的正则表达式不包含选择运算符, 那么 r 1 或 r 2 两边的括号就可以省略. 正则表达式
(Asian|European|North American) (male|female) (black|blue)bird
一共匹配 12 种字符串, 从
Asian male blackbird
到
注:The AWK Programming Language学习笔记